
|
Sibel Somyürek
Gazi University, Turkey
This paper aims to give a general review of existing literature on adaptive educational hypermedia systems and to reveal technological trends and approaches within these studies. Fifty-six studies conducted between 2002 and 2012 were examined, to identify prominent themes and approaches. According to the content analysis, the new technological trends and approaches were grouped into seven categories: standardization, semantic web, modular frameworks, data mining, machine learning techniques, social web, and device adaptation. Furthermore, four challenges are suggested as explanation why adaptive systems are still not used on a large scale: inter-operability, open corpus knowledge, usage across a variety of delivery devices, and the design of meta-adaptive systems.
Keywords: Adaptive educational hypermedia systems; new trends; content analysis, distance education
There are various adaptive systems currently in use in many different industries, from car systems that provide adaptations to increase the comfort and safety of travelers, to e-commerce sites that recommend appropriate products according to similar customer profiles. Adaptive educational hypermedia systems are one of the application areas of adaptive systems that aims to customize educational content and learning paths in e-learning environments to minimize disorientation and cognitive overload problems of students and to maximize learning and efficiency (Ford & Chen, 2001; Brusilovsky, 1998; Höök, 1998; Juvina & Herder, 2005).
Along with developments in information and communication technologies, the increasing use of e-learning worldwide has created a need to restructure web-based learning environments which is an important platform to deliver distance education. One of the main criticisms concerning web-based learning environments is the inability of current systems to meet different users’ particular needs and preferences. This is because these systems offer the same content resources and same sets of links to all users (Brusilovsky, 2003; Moallem, 2007). Another criticism is that users face a number of common difficulties such as disorientation or cognitive overload when studying with these environments (Ahuja, & Webster, 2001; Chen, 2002; Demirbilek, 2004; McDonald & Stevenson, 1998; Rezende & Barros, 2008). The development of adaptive educational hypermedia is an important milestone in e-learning since their potential to resolve these criticisms.
Studies on adaptive educational hypermedia have become popular in recent years, due to the expanded use of e-learning around the world. However, the adoption of these adaptive systems in actual e-learning platforms is still not widespread. One of the main reasons that current educational systems do not offer personalization options has to do with a variety of challenging issues. These challenges are all discussed in the recent field literature and can be grouped into four main thematic categories (Brusilovsky, 2003; Brusilovsky & Henze, 2007; Huang, Wang, & Hsieh, 2012). These categories are inter-operability, open corpus knowledge, usage across a variety of delivery devices, and the design of meta adaptive systems.
The most common challenge involves inter-operability which is the ability of the reusability, sharing, and exchange of knowledge and components in existing educational systems (Brusilovsky & Henze, 2007). Inter-operability makes the development process for adaptive educational hypermedia systems easier and increases their practical value (Caravantes, & Galán, 2011; Brusilovsky & Henze, 2007; Paule, et al., 2008). Inter-operability covers two sub-themes: reusability of resources and reusability of system functions. Reusability of resources means the capability to communicate and exchange data about students, content, pedagogical practices, learning designs, and/or the sequencing of learning activities (Bittencourt et al., 2009; Yessad, Faron-Zucker, & Laskri, 2008; Dicheva & Dichev, 2006). Reusability of system functions means the capability to automatically translate exchanged resources meaningfully and accurately between different systems (Paule, et al., 2008; Caravantes & Galán, 2011).
Interoperability problem becomes more obvious within open corpus knowledge. Open corpus knowledge means a body of dynamically generated knowledge, which “can constantly change and expand” (Brusilovsky & Henze, 2007). In an open corpus knowledge system, resources can be shared with other systems and users can access other systems’ resources to integrate additional learning material (Muntean & Muntean, 2009; Brusilovsky & Henze, 2007). According to the literature (Henze & Nejdl, 2001; Brusilovsky & Rizzo, 2002; Brusilovsky & Henze, 2007; Knutov, De Bra, & Pechenizkiy 2009), traditional adaptation techniques and approaches cannot adequately integrate information taken from the Web. Traditional techniques are useful only in limited contexts, in which the educational systems contain a closed set of resources, and the relationships between these resources are known during the designing process. Thus, researchers have emphasized that the open corpus knowledge problem is one of the main obstacles to the widespread adoption of adaptive hypermedia (Brusilovsky & Henze, 2007).
Due to developments in communications and wireless technologies, educators and researchers have become interested in developing adaptive educational applications for a variety of devices. But the large and growing number of available devices has given rise to a new challenge. Educational environments should be flexible, so that the environments can be delivered with the use of different devices, such as mobile phones, tablets, or netbooks. Therefore, adaptive educational hypermedia systems need to have a detection mechanism that can determine device properties, so the system can adapt its content, presentations, or functions according to the formats and properties of those different devices (Huang, Wang, & Hsieh, 2012).
From the early days of adaptive hypermedia studies, hypermedia programs have offered several content and link adaptation methods. Content adaptation methods include additional, pre-requisite, and comparative explanations; explanation variants; sorting and link adaptation methods include global and local guidance; and global and local orientation support (Brusilovsky, 1998). However, the existing research reveals several strengths and weaknesses among these methods across different contexts (Boyle & Encarnacion, 1994; Brusilovsky & Pesin, 1998; De Bra & Calvi, 1998; Juvina & Herder, 2005). Meta adaptive systems include various adaptation technologies, and they automatically-select the most appropriate adaptation technology for the user and the given context. To make the best technology selection, these systems must be designed to be aware of the limits of each technology (Brusilovsky, 2003).
Although there are several new technological approaches and techniques, many researchers and system developers are not aware of all of them and so continue to use adaptation technologies and approaches dating from the mid-1990s. The purpose of this study is to review recent technological developments relating to adaptive educational systems, which may provide solutions to overcome the challenges involving inter-operability, open corpus knowledge, the usage of different delivery devices, and the design of meta adaptive systems. This study offers three significant conclusions. First, the review of recent field literature provides a clear understanding of relationships between the new technological trends and the associated challenges. That knowledge can be used to highlight directions for future research. Second, the results will inform designers and researchers about recent technological approaches used for the design and development of adaptive systems. That information can provide familiarization, first stage of technology adoption. Familiarization is important for the creation of updated and improved adaptive systems, which will in turn encourage wider adoption of these adaptive systems in actual e-learning platforms. Finally, this study will contribute to open and distance learning because of several reasons. According to Sherry’s (1995) review, one of the most important factors which affect distance education systems’ success or failure is learning characteristics. Learners differ in their behavior and the processes from each other and interacting at a distance makes these differences more important. Adaptive educational hypermedia provides several methods and technologies to offer appropriate solutions for each individual. For those reasons, adaptive systems are critical for distance education. Furthermore, today the most important and commonly used delivery platform for distance education systems is web based systems. Adaptive educational hypermedia can also be seen as a solution to overcome usability problems that users face in web systems. So this study is beneficial for distance education literature to inform designers and educators to select the right technology to deliver courses via web based systems.
Content analysis was the method used to identify recent technological trends and issues concerning adaptive educational hypermedia systems. This research method is used to analyze text data by the classification of important structures from large amounts of content that represent similar meanings (Weber, 1990). “Content analysis is an empirically grounded method, exploratory in process and predictive or inferential in intent” (Krippendorff, 2012, p. 1). Researchers identify themes or patterns through interpreting the content of data subjectively. There are different approaches for qualitative content analysis, such as conventional, directed and summative (Hsieh & Shannon, 2005). These approaches are different from each other according to methods for coding. This study is conducted by using conventional content analysis which means code categories did not determine before review process and they are derived from the textual data. In this study eight steps for systematic analysis are used. These steps are (Zhang & Wildemuth, 2009):
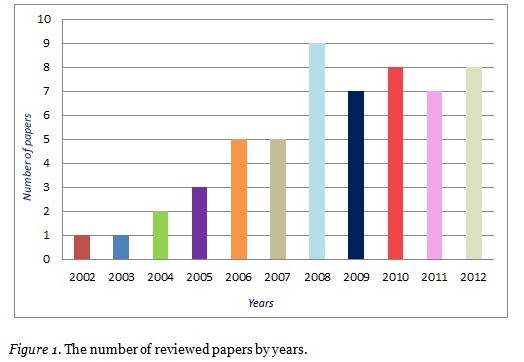
The search and selection procedures were conducted in three stages. First, accessible articles were located by searching with the keyword “adaptive educational hypermedia” in the following computerized bibliographic databases: Academic Search Complete, the Educational Research Information Center (ERIC), and Science Direct. These databases were chosen because they are all covering studies related to educational technology. Then, essential criteria were determined to decide whether to include or exclude located studies in this literature analysis. According to the criteria listed in Table 1, 78 publications obtained in the search were examined by two different researchers independently. Cohen’s alpha among the researchers was 0.96 (p <0.001) regarding whether a study was relevant or not for this analysis. The researcher then eliminated eight which were duplicates and 14 that did not meet the selection criteria. The remaining 56 studies were used in this review study. These 56 papers were read by the researcher and the parts of papers that are related with new technological trends were noted. Codes are defined during data analysis and these data driven codes were associated for the noted parts of the papers. After coding the whole data, similar codes were combined and finally themes and patterns were identified. Figure 1 shows the distribution of the number of these reviewed papers by years.

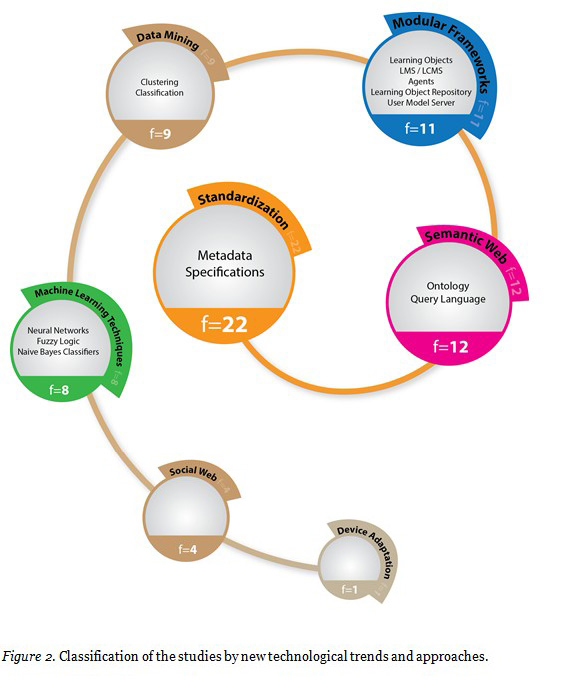
The findings regarding new technological trends and approaches in the reviewed studies are presented in Figure 2. Each of these findings is explained in detail below.
The new technological trends and approaches were grouped into seven categories. These themes are shown in Figure 2, along with sub-themes and related study frequencies. Notably, 14 of the 56 studies do not describe a new technological approach.
As can be seen in Figure 2, among the 56 studies the most popular technological trend was standardization. The other technological trends, in descending order of popularity, are semantic Web, modular frameworks, data mining, machine learning techniques, social Web, and device adaptation. The image format only permitted the grouping of sub-themes under one main theme at a time. However, some of the sub-themes in the image can be grouped under more than one theme. For example, although studies examining ontology are classified under the semantic Web theme, these same studies also may be included in the standardization theme. Similarly, studies using similarity comparisons that are based on learners’ actions to adapt e-learning recommender systems are listed under the theme of data mining, but they are also related to the social Web theme, because that includes the making of calculations and inferences according to collaborative student models.
The main goal of standardization is to develop a set of widely adopted and interchangeable features, to make instructional contexts compatible with each other, inter-operable, and repeatable. According to the reviewed literature, standardization includes two sub-themes: metadata and specifications. In an adaptive system, in order to discover and publish the most appropriate content for different learners (bearing in mind that the content must be compatible with the students’ characteristics), metadata that defines each learning object and that describes each learner’s aspects are needed. Using metadata, the body of learning content, the learners’ profiles, and different learning contexts can be easily integrated into many adaptive systems (Ruiz, et al., 2008; Tseng, et al., 2008; Cristea, 2004).
The creation of the Sharable Content Object Reference Model (SCORM) arose from increasing needs for common guidelines for content development, for semantic annotations, and for rules which specify an order of learning objects. The first version of SCORM was published in 2000, and since that time it has become widely used for the development, packaging, and delivery of digital learning materials and courses (Ruiz, et al., 2008, Aroyo, Pokraev & Brussee, 2003). Several studies have utilized standardization while developing adaptive systems. For example, Tseng et al. (2008) proposed an adaptive system framework based on SCORM that can be used to transform pedagogical resources into learning objects and to adapt those learning objects to fit students’ profiles. Due to standardization efforts, different specifications have been developed for users and content profiles. These specifications are listed in the following:
Karampiperis, Lin, and Sampson (2006) used elements of the IMS LIP specification to store data on learners’ working memory capacities and inductive reasoning abilities. Furthermore, they also used the IEEE LOM standard to find the best learning objects to match their learners’ working memory capacities. Sjoer and Dopper (2006) indicated the importance of learning objects metadata for constructing meaningful and relevant learning experiences. They also examined problems relating to the creation of learning objects by teachers working collaboratively. They stated that the design team in their study faced difficulties when attempting to select appropriate learning object metadata, which finally included 80 data elements grouped in 9 categories (IEEE 2002). Lazarinis, Green, and Pearson (2010) used the IMS QTI standard to code tests and questions in their study of an adaptive testing system. Their adaptations were made in accordance with test participants’ performances, prior knowledge, goals, and preferences. Burgos, Tattersall, and Koper (2007) examined how the IMS Learning Design (LD), which is a meta-language used to design learning units, can be used for eight types of adaptation. They stated that four adaptations were well supported by the IMS LD, but four others were only partially supported. Wolpers, et al. (2007) collected and analyzed observations about users’ attention spans to create improved and personalized services. They developed a contextualized attention span metadata schema, based on an open specification called attentionXML. The needed data about how people use information was gathered from several platforms, such as browsers, web pages, and news feeds.
Semantic Web technologies have also become a popular topic in recent studies (Aroyo & Dicheva, 2004). The reviewed studies on this topic cover two sub-themes: ontology and query language. Semantic Web technologies generally offer methods to formalize and share knowledge (Jovanic, et al., 2009, Vesin, et al., 2012; Dolog and Nejdl, 2007). Ontologies can provide a common terminology to enable sharing across multiple systems (Vesin, et al., 2012). ”Ontologies can be combined, shared, easily extended, and used to semantically annotate different kinds of resources” (Jovanic, et al., 2009). They are constructed with standardized languages, such as RDF and OWL. SPARQL, a RDF query language, is used to express queries across ontologies. SPARQL is considered to be one of the key technologies of the semantic Web and is utilized for querying the knowledge repositories in adaptive educational systems. Inference mechanisms or teaching models of adaptive systems can use query language to filter resources according to their relevance to a domain model, user model, or other parameters.
Several studies have focused on developing an approach, framework, and/or system that uses semantic Web technologies (Yaghmaie and Bahreininejad, 2011; Vesin, et al., 2012; Caravantes and Galán, 2011). For example, Vesin, et al. (2012) proposed a new approach for effective personalization that uses semantic Web technologies. They developed a tutoring system, named Protus 2.0, to support the learning of programming languages in different contexts. This system involved the use of several ontologies, such as a domain ontology, a learner model ontology, a task ontology, and a teaching strategy ontology. It also included adaptation rules to present knowledge and inference engines for reasoning. Similarly, most of the studies on the semantic Web used several ontologies for modeling (Behaz and Djoudi, 2011; Yessad, Faron-Zucker, and Laskri, 2008). In some studies, the aim was to integrate models from cognitive theories or personality theories with ontologies (Caravantes and Galán, 2011; Behaz and Djoudi, 2011). For example, the MEDYNA systems learner ontology was combined with the Myers-Briggs Type Indicator to describe learners (Behaz and Djoudi, 2011). Some studies discussed the synergic use of semantic and social technologies to make the development process easier and to solve technical issues (Jovanic, et al., 2009; Bittencourt, et al., 2009). Jovanic, et al. (2009) emphasized the importance of mapping between ontologies, so as not to restrict adaptive systems to local ontologies. If only local ontologies are used, systems that include the same or similar knowledge may not be able to transfer their content to other systems. The proposal of Paule, et al. (2008) was based on folksonomy, due to the lack of a clear ontology for e-learning. Cristea (2004) presented an adaptive educational hypermedia authoring framework, and developed this authoring system (MOT) using semantic Web technologies such as tags, a rating system, and feedback. Cristea and Ghali (2011), in their follow-up study, developed MOT2 by extending the previous system to offer extra material to students, which was selected according to the students’ interactions with content and other people. Dicheva and Dichev (2006) sought to develop an ontology for learning object repositories, including resources on the Web. For this purpose, they described TM4L, which is an environment in which one can build, maintain, and utilize standardized e-learning repositories. In this environment, users may capture, access, and share knowledge by means of its efficient, searchable, shareable, and interchangeable features. Some research studies also included experimental or case studies, in order to illustrate or examine the features of their own proposed model/system (Bittencourt, et al., 2009; Cristea and Ghali, 2011).
Due to the potential of modular course frameworks, which permit individuality, flexibility, exchangeability, and the extension of a system, they are seen as an effective solution for shortcomings found in complete learning designs (Tseng, et al., 2008). The reviewed studies that used modular frameworks in adaptive systems covered five sub-themes. These themes are learning objects, learning management systems/learning content management systems (LMS/LCMS), agents, learning object repositories, and user model servers.
An e-learning environment must be designed as a collection of learning objects rather than as a whole learning package, to offer appropriate content for different learners according to their characteristics (Kay, 2000). Learning objects are one of the essential parts of modular e-learning systems. E-learning platforms such as LMS/LCMS or learning object repositories are used to deliver learning objects. Some adaptive hypermedia studies have focused on the enhancement of an existing LMS/LCMS, which uses a number of teacher and student activities to create a learning process (Despotovic-Zrakic, et al., 2012; Verbert, et al., 2012). One of the widely stated problems concerning popular e-learning management systems such as Blackboard, WebCT, Moodle, or LAMS is that they offer their users few, or in most cases no, personalization options (Cristea and Stash, 2006). So, researchers have tried to enhance them, using add-on adaptive functions.
In some studies, a multi-agent concept was employed to include certain properties of agents, such as autonomy, pre-activity and cooperation (Yaghmaie and Bahreininejad, 2011; Aroyo & Dicheva, 2004). For example, Yaghmaie and Bahreininejad (2011) suggested a framework to build an adaptive learning management system based on multi-agent systems. They used both SCORM 2004 and semantic Web ontology in the framework. The proposed architecture included four agents: a context management agent, a content selector agent, a content organizer agent, and a content presenter agent. In adaptive systems with multiple agents, information about users, the domain, the teaching model, problems, or any other application-related items can be exchanged with other systems by the use of independent components.
Some modular adaptive learning system architectures include learning object repositories that facilitate the retrieval and sharing of desirable learning objects (Tseng and Su, 2008). To successfully share a user model acquired by one system with other applications, Kabassi, Virvou, and Tsihrintzis (2007) proposed the creation of a user-modeling server. They suggested that this server would make the sharing and maintenance of user models easier and would enable their wider acceptance, due to the advantages of Web services that facilitate convenient, reliable, and easy information exchanges.
Data mining is one of the techniques used to construct an understandable structure by means of analyzing large quantities of data (Despotovic-Zrakic, et al., 2012). The reviewed studies on data mining covered two sub-themes: clustering and classification. Clustering was used in some studies to assign similar students to groups so that they all feature similar characteristics (Despotovic-Zrakic, et al., 2012). For example, Ghauth and Abdullah (2011) used two filtering approaches, one content-based and the other collaborative, in their proposed e-learning recommender system. In the modeling phase in their system, a content profile builder and a rating profile builder were used. The content profile builder queried keywords in the learning materials from the document repository in order to calculate the documents’ similarity. The rating profile builder queried the good learners’ ratings in the ratings repository. Khribi, Jemni, and Nasraoui (2009) described an automatic personalization approach that used the same filtering methods to recommend learning resources. When a student submits a keyword to the search engine, with respect to the similarity of the contents to the submitted term vector the results are sorted. Then, active learners were clustered into groups based on their common interests and skills levels. These interests and skills levels were computed by analyzing similarities and dissimilarities among their navigation histories. According to content-based and collaborative filtering, recommendations are made for each user. Karampiperis, Lin, and Sampson (2006) addressed an adaptive learning-content selection process that was based on the learners’ cognitive characteristics. One of the key elements in their proposed architecture was the cognitive trait model. This focuses on the learner’s navigational patterns to identify his/her cognitive characteristics. Ortigosa, Paredes, and Rodriguez (2010) attempted to provide an adaptive hierarchical questionnaire based upon Felder-Silverman’s learning styles, to reduce the number of required answers. For this purpose, they used a classification technique employing as few questions as possible to determine the learning style of a given student. In this case, a classifying C4.5 algorithm for building decision trees was utilized. Özpolat and Akar (2009) also proposed an automated learner modeling system based on the Felder–Silverman learning style model. They used the naïve Bayesian tree classification method to analyze students’ learning styles.
Machine learning techniques include three sub-themes: neural networks, fuzzy logic, and the naïve Bayes classifier. Neural networks are one of the most preferred techniques to recognize patterns in users’ navigation paths or questionnaire responses (Lo and Shu, 2005; Yeh, 2005 ). Lo and Shu (2005) developed a multi-layered, feed-forward neural network to automatically categorize users’ learning styles by analyzing their online browsing trails in the learning environment. In a similar study conducted by Yeh (2005), a multi-layered, feed-forward neural network model was also used. This model assessed the users’ metacognitive knowledge levels by applying a set of data obtained from their browsing behaviors. In another experimental study, Stathacopoulou, et al. (2007) presented a neural network-based fuzzy modeling approach to analyze the learning styles of students. Botsios, Georgiou, and Safouris (2008) used Bayesian networks in order to analyze users’ learning styles according to David Kolbs’s learning style model. Huang, Wang, and Hsieh (2012) developed an adaptive mobile learning system to perform content adaptations according to the students’ knowledge levels, learning styles, and their different electronic delivery devices. They also used Bayesian networks both in their knowledge diagnosis module and in their learning-style module. The knowledge diagnosis module evaluated the knowledge levels of the users and discovered probable misconceptions, while the learning-style diagnosis module was used to identify learning styles.
As knowledge in the 21st century is often personal, social, distributed, and dynamic in nature, the social Web has become very popular in recent years. Some studies have examined how the social Web may be used to enrich adaptive educational hypermedia systems (Klamma, et al., 2007; Chatti, Jarke, and Specht, 2010; Jovanic, et al., 2009). For example, Chatti, Jarke, and Specht (2010) discussed the 3P learning model, which includes three core features: personalization, participation, and knowledge-pull. They presented a social software-supported learning framework based on social Web concepts and software technologies, which illustrates the 3P learning model in action. Cristea and Ghali (2011) extended the My Online Teacher 2.0 adaptive system to combine peer recommendations with content adaptation. This system successfully integrated Web 2.0 components, such as tags, a rating system, and feedback, for providing more specific recommendations to learners. These recommendations were based both on their interactions with the content and with other people. Jovanic, et al. (2009) focused on merging the social Web with semantic Web paradigms, and discussed the major benefits of this integration for each component of adaptive educational systems. They stated that social Web technologies can be effectively used to refine and/or update ontologies. At the same time, the structured knowledge of semantic Web technologies may be useful for social Web applications.
Mobile devices such as notebooks, surfaces, smart phones and tablets are becoming widely available. Therefore, mobile learning is seen as a new medium that can be used for educational purposes. There is an increasing need and demand to adaptively change the contents of web-based learning environments to use them with a variety of devices (Huang, Wang, and Hsieh, 2012). Making adaptive systems independent upon the environment is referred to as a higher order of adaptation (Knutov, De Bra, and Pechenizkiy, 2009). Huang, Wang, and Hsieh (2012) presented an adaptive mobile learning system that provides adaptation capabilities to suit both specific learners and devices. Adaptations for specific learners are conducted according to the learners’ characteristics and abilities. Adaptations for specific devices are conducted according to the device profile by a Java-based content adaptation mechanism. A device detection mechanism accesses the database and finds the most appropriate content for the given device.
Along with the popularization of web based environments, the distribution and implementation of distance education have become easier and faster. Web based systems make it possible to provide main principles of distance education theory such as providing independence of the student, overcoming space-time barriers and offering freedom of choice (Simonson, Schlosser & Hanson, 1999; Duffy & Kirkley, 2004; Holmberg, 1985; Keegan, 1986). Furthermore, web systems are also seen as an important shift for the target audience of distance education, who is unable to or do not prefer to attend face-to-face learning environments (Holmberg, 1985). The increase of the offered content and more responsibility of users to access and organize these contents, caused them to face some usability problems such as disorientation and cognitive overload in web based learning environments (Ahuja, & Webster, 2001; Chen, 2002; Demirbilek, 2004; McDonald & Stevenson, 1998; Rezende & Barros, 2008; Jonassen, & Grabinger, 1990). Adaptive educational hypermedia systems are designed to minimize these usability problems and to maximize learning by providing personalization to each learner. However, their adoption in actual e-learning platforms is not widespread. Challenges involving inter-operability, open corpus knowledge, the usage of various delivery devices, and the design of meta adaptive systems are seen as major reasons for this situation. In order to overcome these challenges and facilitate the widespread use of adaptive e-learning platforms, recent research studies were examined and summarized to provide information for future work. According to the review results, seven technological trends and approaches emerged: standardization, the semantic Web, modular frameworks, data mining, machine learning techniques, the social Web, and device adaptations.
Standardization provides a reliable method to make modular knowledge packages and other components interchangeable among different adaptive educational hypermedia. It enables the reuse of semantic annotations that are associated with the learning content, learners’ profiles, and/or a learning design. Annotations facilitate the easy addition or removal of new learning objects in learning object repositories. It also helps easy exchange of application interfaces, components and/or system functions between similar systems. With standardized metadata, documents can be transmitted across systems and a collection of commonly used documents can be constructed, to make an open corpus adaptive hypermedia system. Finally, standardization also allows educational services and systems to be delivered using a wider range of adapted mobile devices. Because of these reasons, standardization facilitates three major challenges, inter-operability, open corpus knowledge, and the usage of various delivery devices for instruction.
Semantic Web technologies are designed to provide more effective and reliable mechanisms than previously generated standards, to share knowledge among various environments (Jovanic, et al., 2009). In this context, ontologies can be used to describe learners’ profiles, cases, and learning resources. The ontologies also can be extended via mapping, to eliminate the limitation of using an ontology only in the one system for which it was developed (Jovanic et al., 2009). Beyond providing a common and general standard via the employment of ontologies, semantic Web architecture – which contains reasoning engines, languages rules, and logical formalisms – also allows machines to automatically read and process semantics, and to interpret ontologies. Semantically rich data models allow a subject classifier to be embedded in a concept model, which also can be machine processed. They thereby offer significant advantages for adapting content during specialized training (Jovanic, et al., 2009; Yessad, Faron-Zucker, and Laskri, 2008; Dolog and Nejdl, 2007; Brusilovsky and Henze, 2007). For that reason, semantic Web technology is seen as an important solution for both inter-operability and open corpus problems.
Modular frameworks are seen as an effective solution when creating adaptive Web-based systems that share each other’s resources and components (Aroyo & Dicheva, 2004). The modular approach involves the development of educational systems as a set of learning objects, which resides in e-learning object repositories or in LCMSs. This sort of framework is essential for the sharing of resources or system functions among various environments, because it entails the stockpiling of various material/parts from different e-learning systems.
As stated in results, several studies focused on data mining approaches to search for similarities, using data obtained from navigation tracks or metadata. Clustering involved the discovery of previously unknown patterns, which could be used to create groups of data or of users. Classification involved analyzing known structures in order to make recommendations according to the results. With these approaches, similar content and learner groups can be created, and new contents/users can be suitably placed among these groups. Content-based filtering and collaborative filtering are the two main methodologies used to suggest appropriate materials for the learners. Collaborative filtering is based on similarity matching between students and provides results that fit their shared characteristics. Content-based filtering is based on similarity matching within learning objects’ metadata to provide results of similar content. Both methods support inter-operability and open corpus knowledge, as they identify meaningful relations between existing data. They are also useful for meta adaptive systems, because they enable the system to find the best adaptations according to an automated analysis of large amounts of data.
Machine learning techniques are commonly used to recognize patterns in users’ navigation paths or in questionnaire responses. This facilitates the creation of categories to classify the users’ learning styles, metacognitive knowledge, and/or their knowledge levels. Neural networks, including the Bayesian network and fuzzy logic, are detection technologies used in adaptive recommender systems. Machine learning techniques facilitate inter-operability, open corpus knowledge, the design of meta adaptive systems, and the usage of a variety of delivery devices due to its modular structure.
Social Web technologies are important for obtaining knowledge about users, such as their preferences and interests, and for finding similarities among preferred contents. People tend to follow the footsteps of other people who have similar interests. Using this natural tendency, a document may be indexed in the existing hyperspace by a community of users (Wexelblat and Maes, 1999; Hsiao et. Al., 2013). This approach is similar to collaborative filtering systems, because it relies on how a document is used instead of its content (Brusilovsky and Henze, 2007). Also, users can construct ontologies by tagging contents individually. Social Web technologies facilitate the creation and maintenance of ontologies or other specifications that are otherwise expensive and time-consuming. In order to generate open corpus and inter-operable systems, folksonomies and other social Web technologies can be used.
Device adaptation is intended to make a teaching system as flexible as possible, so that it can work on different devices. So, one person who possesses different devices can use her/his different tools to access the same learning system. At the same time, different people can use the same learning system independently with their personal devices. Device adaptations include detection mechanisms to determine device properties. According to the device properties, content and presentation formats can be adjusted (Huang, Wang, and Hsieh, 2012).
As a result, these seven technological trends are seen as important solutions to deal with major challenges. For that reason, these trends and approaches should be considered when developing new adaptive hypermedia systems. The results of this analysis also should be supported with further empirical investigations that focus on comparing the effects of different technological trends and approaches to solve each challenging issue.
Ahuja, J. S. and Webster, J. (2001). Perceived disorientation: An examination of a new measure to assess web design effectiveness. Interacting with Computers, 14(1), 15-29.
Aroyo, L., Pokraev, S., and Brussee, R. (2003). Preparing SCORM for the semantic web. Paper presented at the International Conference on Ontologies, Databases and Applications of Semantics (ODBASE’03), 3-7, November, Catania, Sicily.
Aroyo, L., & Dicheva, D. (2004). The new challenges for e-learning: The educational semantic web. Educational Technology & Society, 7(4), 59-69.
Behaz, A. and Djoudi, M. (2011). Ontological representation models for adaptive hypermedia construction. International Review on Computers & Software, 6(2), 199-205.
Bittencourt, I. I., Costa, E., Silva, M. and Soares, E. (2009). A computational model for developing semantic web-based educational systems. Knowledge-Based Systems, 22(4), 302–315.
Boyle, C. and Encarnacion, O. (1994). MetaDoc: An adaptive hypertext reading system. User Modeling and User-Adapted Interaction, 4(1), 1-19.
Botsios, S., Georgiou, D. and Safouris, N. (2008). Contributions to adaptive educational hypermedia systems via on-line learning style estimation. Journal of Educational Technology & Society, 11(2), 322-339.
Brusilovsky, P. (1998). Methods and techniques of adaptive hypermedia. In P. Brusilovsky, A. Kobsa & J. Vassileva, Adaptive hypertext and hypermedia (pp. 1-44). Boston: Kluwer Academic Publishers.
Brusilovsky, P. (2003). Adaptive navigation support in educational hypermedia: The role of student knowledge level and the case for meta-adaptation. British Journal of Educational Technology, 34(4), 487-497.
Brusilovsky, P. and Henze, N. (2007). Open corpus adaptive educational hypermedia. In P. Brusilovsky, A. Kobsa and W. Neidl, The adaptive web: Methods and strategies of web personalization. Lecture Notes in Computer Science, Vol. 4321, (pp. 671-696). Berlin Heidelberg New York: Springer-Verlag.
Brusilovsky, P. and Pesin, L. (1998) Adaptive navigation support in educational hypermedia: An evaluation of the ISIS-Tutor. Journal of Computing and Information Technology, 6(1), 27-38.
Brusilovsky, P. and Rizzo, R. (2002) Using maps and landmarks for navigation between closed and open corpus hyperspace in Web-based education. The New Review of Hypermedia and Multimedia, 9, 59-82.
Burgos, D., Tattersall, C. and Koper R. (2007). How to represent adaptation in e-learning with IMS learning design. Interactive Learning Environments, 15(2), 161–170.
Caravantes, A., and Galán, R. (2011). Generic educational knowledge representation for adaptive and cognitive systems. Journal of Educational Technology & Society, 14(3), 252-266.
Chatti, M. A., Jarke, M. and Specht, M. (2010). The 3P learning model. Educational Technology & Society, 13(4), 74–85.
Chen, S. Y. (2002). A cognitive model for non-linear learning in hypermedia programs. British Journal of Educational Technology, 33(4), 449-460.
Cristea, A. & Stash, N. (2006). AWELS: Adaptive web-based education and learning styles. In Proceedings of the Sixth International Conference on Advanced Learning Technologies (ICALT’06). July 5-7, 2006. IEEE, Kerkrade, The Netherland.
Cristea, A. I. (2004). What can the semantic web do for adaptive educational hypermedia? Educational Technology &. Society, 7(4), 40-58
Cristea, A I., and Ghali, F. (2011). Towards adaptation in e-learning 2.0. New Review of Hypermedia and Multimedia, 17(2), 199–238.
De Bra, P. and Calvi., L. (1998). Towards a generic adaptive hypermedia system. In second workshop on adaptive hypertext and hypermedia (Hypertext’98), June 20-24, 1998, Pittsburgh, USA, pp. 5-11.
Demirbilek, M. (2004). Effects of interface windowing modes and individual differences on disorientation and cognitive load in a hypermedia learning environment. Unpublished doctoral dissertation, Florida University.
Despotović-Zrakić, M., Marković, A., Bogdanović, Z., Barać, D., & Krčo, S. (2012). Providing adaptivity in Moodle LMS courses. Educational Technology & Society, 15(1), 326–338.
Dicheva, D., and Dichev, C. (2006). TM4L: Creating and browsing educational topic maps. British Journal of Educational Technology, 37(3), 391–404.
Duffy, T. M., & Kirkley, J. R. (2004). Learning theory and pedagogy applied in distance learning: The case of Cardean University. Learner-centered theory and practice in distance education: Cases from higher education, 107-141.
Ford, N. and Chen, S. Y. (2001) Matching/mismatching revisited: An empirical study of learning and teaching styles. British Journal of Educational Technology, 32(1), 5-22.
Ghauth, K. I. and Abdullah, N. A. (2011). The effect of incorporating good learners’ ratings in e-learning content-based recommender system. Educational Technology & Society, 14(2), 248–257.
Henze, N. and Nejdl, W. (2001). Adaptation in open corpus hypermedia. International Journal of Artificial Intelligence in Education, 12(4), 325-350.
Holmberg, B. (1985). The feasibility of a theory of teaching for distance education and a proposed theory. ZIFF Papiere 60. ERIC, ED 290013.
Höök, K. (1998). Evaluating the utility and usability of an adaptive hypermedia system. Knowledge-Based Systems, 10(5), 311-319.
Hsiao, I. H., Bakalov, F., Brusilovsky, P., and König-Ries, B. (2013) Progressor: social navigation support through open social student modeling. New Review of Hypermedia and Multimedia, 19(2), 112-131.
Hsieh, H. F. and Shannon, S. E. (2005). Three approaches to qualitative content analysis. Qualitative Health Research, 15(9), 1277-1288.
Huang, H.-C., Wang, T. and Hsieh, F.-m. (2012). Constructing an adaptive mobile learning system for the support of personalized learning and device adaptation. In Proceedings of the 12 the International Educational Technology Conference - IETC 2012, Procedia - Social and Behavioral Sciences (ISSN 1877-0428), 64, 332-341.
Jonassen, D. H., and Grabinger, R. S. (1990). Problems and issues in designing hypertext/hypermedia for learning. In D. H. Jonassen & H. Mandl (Eds.), Designing hypermedia for learning (pp. 3-26). Heidelberg: Springer-Verlag.
Jovanović, J. , Gašević, D., Torniai, C., Bateman, S. and Hatala, M. (2009). The social semantic web in intelligent learning environments: State of the art and future challenges. Interactive Learning Environments, 17(4), 273-309.
Juvina, I. and Herder, E. (2005). The impact of link suggestions on user navigation and user perception. In Proceedings of the User Modeling 2005: Tenth International Conference (UM2005), Edinburgh, United Kingdom.
Kabassi, K., Virvou, M., and Tsihrintzis, G. A. (2007). Web services user model server performing decision making. International Journal of Pattern Recognition and Artificial Intelligence, 21(2), 245–264.
Karampiperis, P., Lin, T. and Sampson, D. G. (2006). Adaptive cognitive‐based selection of learning objects. Innovations in Education and Teaching International, 43(2), 121–135.
Kay, J. (2000). User interfaces for all. In User modeling for adaptation (pp. 271–294). Human Factors Series. Lawrence Erlbaum Associates, Inc., http://www.cs.usyd.edu.au/~judy/Homec/Pubs/ch18.pdf
Keegan, D. 1986. The foundations of distance education. London: Croom Helm.
Khribi, M. K., Jemni, M., and Nasraoui, O. (2009). Automatic recommendations for e-learning personalization based on web usage mining techniques and information retrieval. Educational Technology & Society, 12(4), 30–42.
Krippendorff, K. (2012). Content analysis: An introduction to its methodology. Sage.
Klamma, R., Chatti, M. A., Duval, E., Hummel, H., Hvannberg, E. H., Kravcik, M., Law, E., Naeve, A., and Scott, P. (2007). Social software for life-long learning. Educational Technology & Society, 10(3), 72-83.
Knutov, E., De Bra, P. and Pechenizkiy, M. (2009). AH 12 years later: A comprehensive survey of adaptive hypermedia methods and techniques. New Review of Hypermedia and Multimedia, 15(1), 5–38.
Lazarinis, F., Green, S. and Pearson, E. (2010). Creating personalized assessments based on learner knowledge and objectives in a hypermedia Web testing application. Computers & Education, 55(4), 1732–1743.
Lo, J.-J. and Shu P.-C. (2005). Identification of learning styles online by observing learners’ browsing behaviour through a neural network. British Journal of Educational Technology, 36(1), 43–55.
Mcdonald, S. and Stevenson, R. J. (1998). The effects of text structure and prior knowledge on navigation in hypertext. Human Factors, 40(1), 18-27.
Micarelli, A. and Sciarrone, F. (1996). A case-based system for adaptive hypermedia navigation. Advances in Case-Based Reasoning Lecture Notes in Computer Science Volume 1168, 266-279.
Moallem, M. (2007). Accommodating individual differences in the design of online learning environments: A comparative study. Journal of Research on Technology in Education, 40(2), 217-245.
Muntean, C. H. and Muntean, G.-M. (2009). Open corpus architecture for personalised ubiquitous e-learning. Personal and Ubiquitous Computing, 13(3), 197-205.
Ortigosa, A., Paredes, P. and Rodriguez, P. (2010). AH-questionnaire : An adaptive hierarchical questionnaire for learning styles. Computers & Education, 54(4), 999–1005.
Özpolat, E. and Akar, G. B. (2009). Automatic detection of learning styles for an e-learning system. Computers & Education, 53(2), 355–367.
Rezende, F. and Barros, S. d. S. (2008). Students’ navigation patterns in the interaction with a mechanics hypermedia program. Computers & Education, 50(4), 1370–1382.
Ruiz, M.P.P., Diaz, M. J. F., Soler, F. O. and Perez, J. R. P. (2008). Adaptation in current e-learning systems. Computer Standards & Interfaces, 30, 62–70.
Sherry, L. (1995). Issues in distance learning. International Journal of Educational Telecommunications, 1(4), 337-365.
Simonson, M., Schlosser, C., and Hanson, D. (1999). Theory and distance education: A new discussion. American Journal of Distance Education, 13(1), 60-75.
Sjoer, E., and Dopper, S. (2006). Learning objects and learning content management systems in engineering education: implications of new trends. European Journal of Engineering Education, 31(4), 363–372.
Somyürek, S. (2009). Student modeling: Recognizing the individual needs of users in e-learning environments. Uluslarası İnsan Bilimleri Dergisi, 6(2), 429-450.
Stathacopoulou, R., Grigoriadou, M., Samarakou, M. and Mitropoulos, D. (2007). Monitoring students ’ actions and using teachers ’ expertise in implementing and evaluating the neural network-based fuzzy diagnostic model. Expert Systems with Applications: An International Journal, 32(4), 955–975.
Tseng, S.-S., Su, J.-M., Hwang, G.-J., Hwang, G.-H., Tsai, C.-C., and Tsai, C.-J. (2008). An object-oriented course framework for developing adaptive learning systems. Educational Technology & Society, 11(2), 171-191.
Verbert, K., Ochoa, X., Derntl, M., Wolpers, M. Pardo, A. and Duval, E. (2012). Semi-automatic assembly of learning resources. Computers & Education, 59(4), 1257–1272.
Vesin, B., Ivanovic, M., Klašnja-Milicevic, A. and Budimac, Z. (2012). Protus 2.0: Ontology-based semantic recommendation in programming tutoring system. Expert Systems with Applications, 39(15), 12229–12246.
Weber, R. P. (1990). Basic content analysis. Beverly Hills, CA: Sage.
Wexelblat, A., & Maes, P. (1999). Footprints: history-rich tools for information foraging. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems (pp. 270-277). ACM.
Wolpers, M., Najjar, J., Verbert, K. and Duval, E. (2007). Tracking actual usage : The attention metadata approach. Educational Technology & Society, 10(3), 106-121.
Yaghmaie, M. and Bahreininejad, A. (2011). A context-aware adaptive learning system using agents. Expert Systems with Applications, 38(4), 3280-3286.
Yeh, S.-w. (2005). Assessing metacognitive knowledge in web-based CALL : A neural network approach. Computers & Education, 44(2), 97–113.
Yessad, A., Faron-Zucker, C. and Laskri, M. T. (2008). Ontology-based personalization of hypermedia courses. International Review on Computers & Software, 3(6), 586.
Zhang, Y. and Wildemuth, B. M. (2009). Qualitative analysis of content. Applications of social research methods to questions in information and library science, 308-319.
© Somyürek